Recently, I was working with TMDb movie database API and came across this problem. I wanted to share how I solved it with a little math. We will make another parameter called Score using the Weighted Rating (WR) method to calculate the score of each title.
Overview
- Load movie data into a DataFrame
- Choose a standard to score the titles
- Calculate the rating of all movies that meet the criteria
- Rank the movies in descending order
The Problem
My application needs to show the list of popular movies that the user might like based on the number of ratings and the average rating of that title. Initially, I was just sorting the average rating in descending order because some titles with a very low number of reviews and higher ratings showed up causing irrelevant results.
To solve this I came up with a scoring criteria which will consider both the number of ratings and the average rating on the title.
Scoring Criteria
For selecting the scoring criteria, we first need to consider that
A movie with 1000 ratings and with 8 as the average rating must have a higher score than a movie that has 10 ratings with 9 as the average rating.
To do that I went with this formula of weighted rating
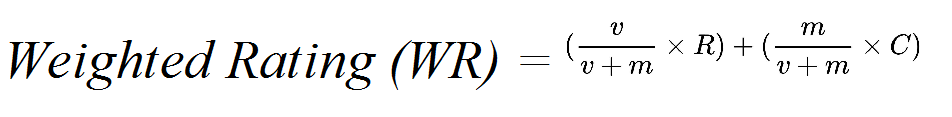
Here, v indicates the total number of times the title has been rated
m represents the minimum requirement of a title to enter the list, basically only titles that have votes higher than m will enter the list
R is the average rating of the title
C is the average rating of all the titles in the list.
DataFrame we have
Now looking at the data we have from the TMDb API response, v, and R are in the data directly as TMDB gives you the number of ratings and average ratings.
Enough talk, lets code now
Firstly let us decide the value of m (minimum ratings to enter the list)
Decide the value of m
You need to remember that the higher the value of m, the condition for a title to enter the list will be that strict.
Here, I chose to use 60% of the votes as the value of m.
m = df['vote_count'].quantile(0.6)
m
---
Out: 50.0Calculating the score
Calculating the average of all the titles is pretty straightforward in Python, just use mean
C = df['vote_average'].mean()
C
---
Out: 5.53838599103349Now calculate the score for each title in the data frame
def weighted_rating(x, m = m, C = C):
v = x['vote_count']
R = x['vote_average']
return (v / (v + m) * R) + ( m / (v + m) * C)
df["score"] = df.apply(weighted_rating, axis = 1)
df.head()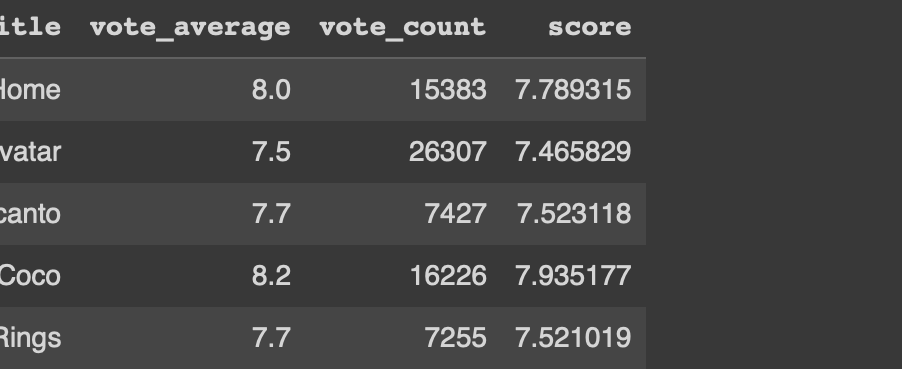
Finally, Sort
Let’s finalize the list by sorting the list with scores of titles in descending order, that will be our final result.
movies = movies.sort_values('score', ascending=False)
movies[:70]This will return the finalized list of movies that have a higher score which means, the movies returned are liked most by many users.
Hope this small article helped you learn a new thing, if you have any questions, comment down below.