Recommendation systems are pretty common these days. Netflix, Prime Video, YouTube, and other streaming platforms use these recommendation systems to suggest a movie that you might like to watch according to your previous watch history.
Hearing this for the first time, got me excited. I started researching and building a simple prototype of a movie recommendation algorithm. I’ll walk you through what I learned from my research and building a working engine.
We’ll also build a system in Python using the sci-kit-learn Python package. You must have some basic knowledge of Python programming and machine learning terms like dataset, model, training, and building a model.
What is a Recommendation System?
Let’s understand with an example Netflix, Asks you to choose a few titles that you like to personalize the experience for you when you first sign up or create a new profile.
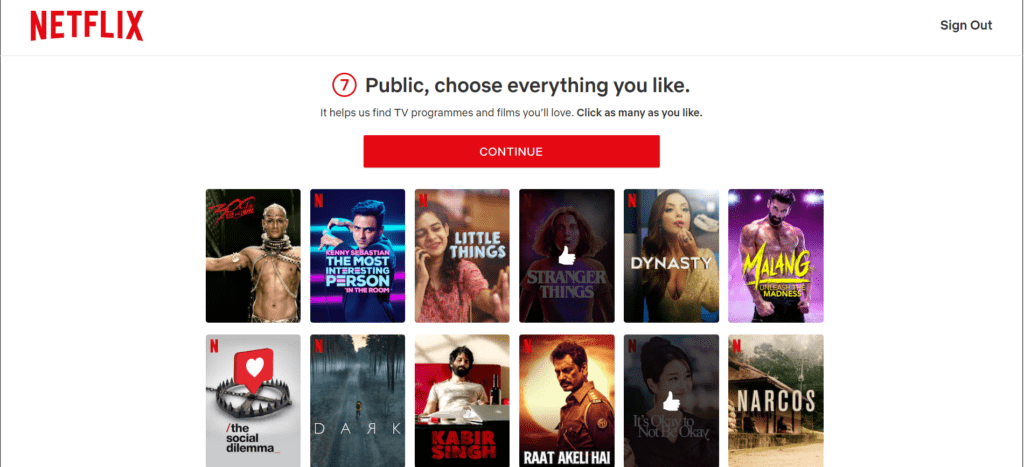
After we select a few titles that we might have watched already on TV or Netflix previously.
Netflix has started to use its recommendation algorithm to predict or suggest the movies or shows that you probably might like to watch.
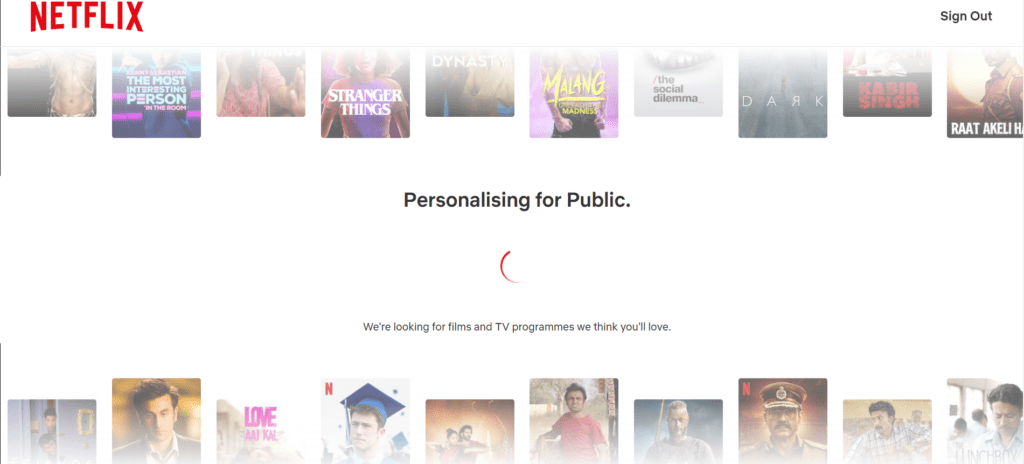
After the algorithm predicts movies that match your interests based on the data you’ve provided previously. It shows similar titles on its home page to improve user experience. This way you don’t need to find a movie that you find interesting
Not only Netflix even YouTube uses some recommendation system to show you relevant videos on your homepage.
Recommendation systems nowadays are more complex and intelligent. Not only on your past activity they work with different kinds of data like suggesting you movies that people nearby your location like, or if it’s a social media platform like Instagram, it might consider what your friends like too.
So, now that you understand how recommendation systems work. Let’s build one ourselves using some simple and free tools.
Building A DIY Simple Recommendation System
There are many kinds of Recommendation systems like
- Popularity-based recommendation system
Like a trending page on YouTube or Netflix that suggests you based on the views and likes or watch time the video or a movie got in the last few days.
- Content-based recommendation system
Once your interest or past activity was collected. In simple, after you watched a video or a movie the recommendation system finds other videos that are similar to the one you’ve already watched and recommends a similar video back to you. This is the system we’re going to be building.
We’ll be taking one input (A movie title) and recommending similar movies as output (back to the user).
- Collaborative Filtering System
This is the recommendation system made popular by Netflix. It’s a peer-to-peer recommendation. If person 1 watches a movie and Person 2 also watches the movie then the movie watched by person 1 later will be suggested to person 2 vice-versa.
This matches the people with similar interests and recommends to each other.
The concept behind our system:
As we’re going to build a content-based recommendation system, our main goal is to find the similarity score between two objects or strings. So, we use a concept called cosine similarity.
Understanding Cosine-Similarity:
Let me explain through a simple example. We have two text arrays as below.
Text One: Jack Rose Jack Jack
Text Two: Rose Jack Rose Rose
How do we get a similarity score between the casts of these two texts? This is where Cosine Similarity Comes into play.
It comes up with a mathematical number of similarities between the casts of the two titles.
The math behind the Cosine Similarity:
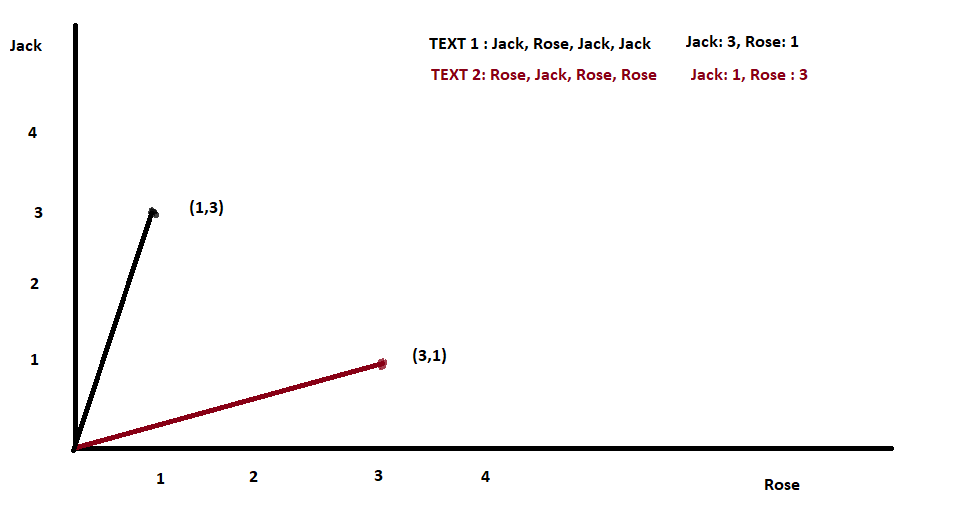
In the graph, I just plotted the word occurrence in the example text.
How do we find the distance between those two vectors? Right, as we learned in high school there are two simple methods for that.
The Angular Distance: The Theta, the angular distance between those vectors,
The Euclidean Distance: Connect the ends of the vectors and the length is the Euclidean distance.
We’re going to use the CosTheta Formula, Which most of you might come across in high school.
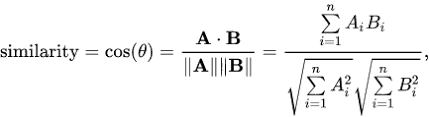
Angular Distance Formula | Cosine Similarity
Okay, Enough theory… Let’s get our hands on the code. Open your favorite text editor (I prefer VS code).
Firstly you need to have a few Python packages installed :
sci-kit-learn
Start by importing some packages
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarityCreate a variable with our two texts :
text =["Jack Rose Jack Jack", "Rose Jack Rose Rose"]We use count vectorizer method to convert our strings into vectors like (3,1) & (1,3).
To count the matrix we’re going to use fit_transform to make a matrix out of our vectors.
cv = CountVectorizer()
count_matrix = cv.fit_transform(text)You can use the print count_matrix.toarray() to see the output matrix. This is going to show a NumPy array something like
[[3,1]
[1,3]]So, we got our vector matrix, now we’re going to use a built-in method called cosine similarity to find the similarity (distance) between these vectors.
smilarity_scores = cosine_similarity(count_matrix)
print(similarity_scores)When you run the program, it shows up an array with the similarity scores. So, this is the concept behind our recommendation system.
As you now know the concept and the basic math behind our system, let’s start building our engine.
Start by creating a new Python file and call it something like recommender.py. Let’s start by importing the required packages.
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarityfrom the previous example, we import pandas and NumPy additionally to process and read our dataset.
For this system, I’ve used the IMDB dataset which I found on kaggle.com, and cleaned it a little bit so we can use it with our system.
You can download the dataset from my repository:
https://github.com/kamaravichow/MovieRecommendations
If you open it in Excel or an office software it should look like this
It has columns with features like cast, keywords, popularity, and more… We’re going to use them to find the similarity between the movies using cosine similarity.
Download the dataset and place it in the folder with our python script.
df = pd.read_csv("movie_dataset.csv")We use pandas to read the CSV dataset and load it to the df (DataFrame) variable.
def get_title_from_index(index):
return df[df.index == index]["title"].values[0] def get_index_from_title(title):
return df[df.title == title]["index"].values[0]These are two helper functions that we’re going to use later.
Now we need to get the feature that we need to use to find a similarity score. For now, I’m going to use keywords, cast, genres, and director.
features = ['keywords','cast','genres','director']You can use other features too according to your requirements.
Let’s now combine all the features into the data frame :
for feature in features:
df[feature] = df[feature].fillna('')You can see the combined features with a print method :
def combine_features(row):
try:
return row['keywords'] +" "+row['cast']+" "+row["genres"]+" "+row["director"] except: print "Error:", row df["combined_features"] = df.apply(combine_features,axis=1)Now let’s initialize count vectorizer to turn them into vectors which we can work with :
cv = CountVectorizer()
count_matrix = cv.fit_transform(df["combined_features"])Getting the similarity based on the count_matrix
cosine_sim = cosine_similarity(count_matrix)Now we take the input from the user. That is the liked movie by the user.
movie_user_likes = "Spectre"
Use the helper function to get the index of the movie from the name of the movie.
movie_index = get_index_from_title(movie_user_likes)
Get the list of similar movies (indices of similar movies):
similar_movies = list(enumerate(cosine_sim[movie_index]))
The list will be in ascending order but, we need the highest similar movie on the top so we sort it into descending order according to the similarity scores.
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)
Now to look at the result, we’ll print the most matched 25 movies to the console(output)
i=0
for element in sorted_similar_movies:
print get_title_from_index(element[0])
i=i+1
if i>25:
break
This will show up the most similar 25 movies to the console.
So, this is how we build a content-based recommendation system using sci-kit-learn and Python.